


We’re not so far from the LLM OS concept explained here or illustrated by Karpathy here; certain startups are attempting it in full like Mainframe. A fully functional LLM OS should be able to call upon and execute the right mixture and sequence of tools to accomplish an abstract goal in the most efficient way possible. Thus, there are key components that must work and with a high enough accuracy that end-to-end tasks can be completed, and each component i.e. browser automation or document processing is a huge standalone task that likely specific startups will target them and a larger, more intelligent model will help orchestrate the task using these tools.
Still, while there is no shortage of startups building AI agents, limitations remain on the effectiveness of these agents—memory, compute, well-designed guardrails, latency, and access to quality tools. Without tools, AI’s are constrained to the data they already have and the interfaces they were built for. Tools enable AI to interact with the external world, such as:
Complex, unstructured data (representing a majority of real-world input from enterprise documents to images and video to audio streams)
Web data (web indexes, browser automation)
Assisted computations (code interpreters, expert answers)
Real world actions (simulated environments AI’s can learn what actions to take, controlling IoT devices)
Operating systems (complex interfaces for humans to learn, but not AI)
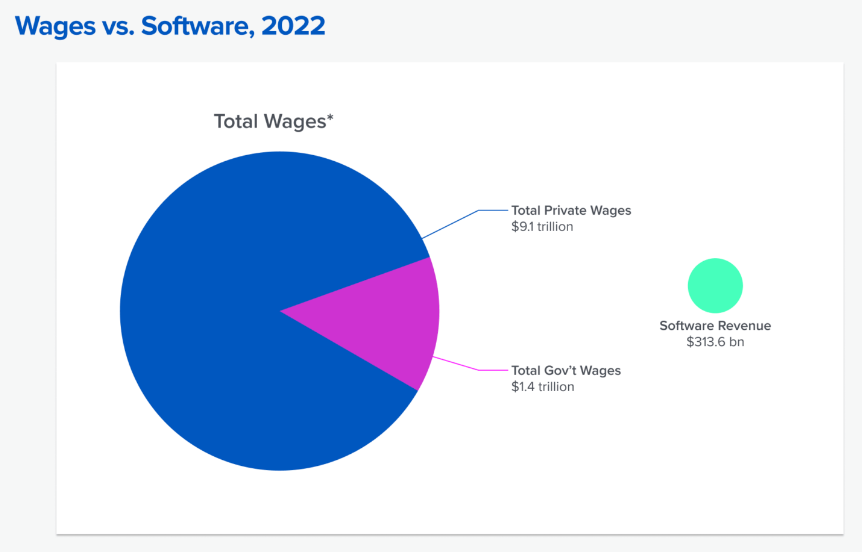
Where the economic accrual will happen eventually is “AI tools that turn into labor” — the true technological inflection point because software in the past couldn’t accomplish this. In the past, software tools have replaced specialized labor as denoted by the Cobb–Douglas production function but AI is allowing software general access to existing capital invested for human labor. Eventually, these AI agents will learn to use the provided tools to master specific human tasks fully autonomously. In fact, we already see signs of improvement in AIs becoming better at using tools: structured decoding and easy, ergonomic SDK fields to use. Thus, the market for these tools is huge compared to the previous wave of SaaS tools as the cost of white collar work is magnitudes larger than pure software revenue.
Unstructured Data
A big unlock lies in unstructured data. So much data is locked up right now, in the form of piles of PDFs, forms, and more in financial corporations, healthcare, and every major sector to the mess of image and video data that if structured and analyzed could hugely advance fields like robotics. It has become apparent that synthetic data isn’t enough to train the newest models, and much of the structured data has already been used. These private organizations are sitting on treasure troves of information and don’t have the right infrastructure to unlock it for LLMs and extract meaningful insights.
There are a few different approaches companies in this space have taken.
Datalab is betting on smaller models that do specific things. For instance, they have one model that does OCR that performs similarly on benchmarks to Google Cloud OCR and then other models for other formats like Marker for PDF to markdown.
Unstructured (Series B) originally took an open source approach (but has over time closed source more as other companies tried to overtake them) but has not focused heavily on developer relations so the self-serve product is not as high quality nor gained widespread adoption. Instead, they have built very custom models for enterprises and the government. Most of their current use cases reside in military and government because the founder, Brian, was ex-CIA and was able to leverage his connections there to sell into all of the different government sectors. Another huge portion of their revenue comes completely via a consulting model since they perform very custom work for each customer’s use case.
Reducto (seed) steps in especially well for complex documents that Unstructured and LlamaParse’s models could not parse due to inability to handle edge cases. Most companies that turn to Reducto have usually tried out the aforementioned and after realizing that they don't work, have started building out their own internal pipelines which are costly to manage and remain SOTA.
There are many wedges into the GenAI data pipeline, ingestion just one of them but nevertheless a good positioning to expand. For instance, some notable companies not included on the map are Superlinked, a pre-product seed-stage company building a vector compute framework; Graphlit and Neum, both RAG-as-a-service; Carbon, an end-to-end solution; and Nomic, with its data curation product Atlas. The RAG part of the pipeline is changing so quickly, however, with so many different approaches depending on the task (whether it is graph-based RAG or RAG-sequence or end-to-end or some other type), what embedding model to use, a different vector database depending on the use case, and at what data scale. Compare this to ingestion: if a company wants to ingest this PDF, it can be ingested the same way whether they’re processing a million or 100 pages. While some of these companies have some document processing in-house, it's very hard to compete with an Unstructured or Reducto, which powers Graphlit’s ingestion, unless their core focus is nailing ingestion and doing it extremely well. In this sense, the cloud APIs are actually the best competition even though they’re inadequate as a general model - Pixtral also came out with some interesting OCR and ingestion capabilities. All in all, the big AI labs will compete for the best generalized document recognition models and vertical companies using cloud APIs for specific document types. If you provide enough raw data to the cloud APIs to build a very custom pipeline, then you can actually make it work for your very custom use case, making it quite hard to beat an engineer working full-time using the outputs of these tools on a very specific narrow use case.
Computer Vision Tools
The other major part of data wrangling for companies, especially in fields like robotics or security, is visual data. It’s easy to see the inflection point here, just look at Meta’s recently released SAM 2. Although there are an assortment of companies here, the most interesting space is VLMs like Moondream (founding team spent 8 years at Amazon, focused on smaller VLMs following on-device tailwinds). DeepDataScience (a deeply technical research team that worked on Grounding Dino) also helps perform computer vision labeling tasks. Another promising stealth startup in this area is Perceptron. Accounting for the applicable markets of autonomous vehicles, surgical assistance, inventory management in retail, security, and government, the AI computer vision market was $17.2B in 2023 growing at a 21.5% CAGR. Existing friction in this market resides in necessary trust in the system and difficulty of implementing systems which often also includes hardware. This has been greatly alleviated by domain-focused companies like FellowAI creating specific CV-based solutions to the supply chain and inventory management space.
Web Access
The last generation of web data tools were mainly web scrapers like ScraperAPI that were pre-Generative AI. We’ve been scraping the web for years, but what holds lots of promise is giving LLMs access to the web and allowing AI agents to take action in the browser where a majority of our knowledge work takes place. Additionally, the long tail of low value scraping tasks, costing a few cents per page don’t represent nearly as large an opportunity as the agentic web tasks to power previously human-only labor.
Browser Automation
The current challenges with browser automation include capacity for long running sessions which is why good human-in-the-loop design is still needed and full browser observability to debug any failures or mishaps that might occur as commonplace with agents. This is definitely a difficult space to find a narrow enough focus to build a good product in, as many have tried and failed such as Sam Altman-backed Induced.
The most popular infra solution in the browser automation space right now is Browserbase, which you can use to bypass website captcha’s and anti-bot protection. The CEO, Paul, a second-time founder, outlined a vision that represents the economic potential for this space well. Currently, browser agents are not really going into production. For a future where agents are inevitable, many companies like Minion but better will be powered by Browserbase. Agentic tasks on the web, unlike web scrapers, are high value use cases that if successfully captured, represent a venture scale opportunity. The worst case would be capturing the long tail of web scraping use cases which would not be as impactful.
Some of the other players in this space are taking alternative approaches. For instance, MultiOn is attempting to build a very broad web-based personal assistant which will likely result in a more brittle product.
Another interesting player in this space is Arc. Originally known as the Browser company for being a more productive, personalized Google Chrome, Arc has gained significant adoption and built new features like Max, which is starting to enter the agentic browser space. Their advantage in owning the browser provides an advantage in direct access to the browser engine which allows for enhanced customization, security, and control over updates compared to building on third-party browsers. While Arc is building a variety of features from search to browser personalization, they’re definitely a player to watch out for in this space.
tinyfish (seed) was started recently by the creators of AgentQL, a query language and a set of supporting developer tools designed to identify web elements and their data using natural language and return them in the shape you define. Experts in this space, unlike many newcomers, tinyfish’s premise is most similar to that of Browserbase, seeking to power the future of browser agents by building robust infrastructure around it.
Web Indexing
Aside from automations, the web also contains a wealth of information albeit very dispersed and difficult for LLMs to use off-the-shelf. Thus, web indexing is particularly important for LLMs, and two companies to compare here are Exa and Perplexity.
Exa has built the most comprehensive semantic search over the internet with a focus on data most relevant to enterprises i.e. company information, research, and news.
Perplexity also indexes the internet daily and provides an API but is more focused on the consumer-facing chat product which produces LLM regurgitations of up-to-date web content.
Because Exa produces raw web data while Perplexity focuses on summarizations tailored for human consumption, Exa’s API is by far the better tool for future agents to use though I’m a fan of Perplexity’s interface for my daily research tasks. LLMs are quickly becoming a commodity; still, value remains in agentic use cases for which LLMs require memorization of the ever-changing web, which ideally will be provided by players in this space. Despite the sophisticated techniques and optimizations Exa and Perplexity use for web-scale RAG, it still remains difficult to envision their path to IPO or venture-scale returns (Google search relies primarily on advertisements for revenue). For instance, what exactly are the highest value use cases given the current pricing models? One issue seems to be that most people do not know what they’re looking for when they search, which is why these products have generally fared better in research settings which are less profitable.
Emerging Tooling
Other areas still in their inception but poised to become key tools for future agents are computation tools like Toolhouse and Composio, OS tools like ChatGPT Desktop and Flow, and real world interaction tools like Zeromatter and Seam.
Computation
Toolhouse is an open source, pre-revenue startup that represents a new generation of PaaS (such as Zapier). There are so many tools out there to assist LLMs with a variety of tasks, and instead of having an LLM write boilerplate code every time, it is much more efficient to have a marketplace of tools ready to be called upon. A similar company founded by IIT engineers—Composio —has been around longer than Toolhouse but also helps ship reliable integrations. Wolfram Alpha, although not a startup, is also fated to be used by agents due to its knowledge base of curated, structured data that come from other sites and books and its ability to perform complex math and science queries which LLMs struggle at. Cognition, although building the LLM part fairly overtly, also straddles this space as a code interpreter, as does E2B which focuses on building the code interpreter.
Operating System
Modern AI, started by ex-Stripe CTO, is building the OS for AI agents, a cloud-based OS where trusted AI agents can work with users across every device. Another startup Flow, which used to be neural interface company Wispr, recently repurposed their software to interact with any desktop and mobile application. The team has quickly launched a new desktop and iOS (beta) product that is gaining traction with consumers. ChatGPT’s Desktop application also eases any screen interactions, and as of now, it is extremely likely that the next OS tool will be built by a creator of an OS like Apple or a major player like OpenAI. Either way, LLMs need access to the OS to be truly all-powerful in a personal device setting.
Physical World Interaction
Finally, one of the biggest gaps in LLMs becoming fully agentic is their ability to take actions in the real world. This can look like simulation software (an expected $15B market by 2026) or IoT APIs, for instance. Zeromatter, a hot startup in this sector, has recently raised a Series A from Bedrock at a $300M valuation primarily due to a very strong team—the heads of Tesla’s simulation team joined the team and are rivaling incumbents like Applied Intuition. Tools enabling these AIs to plan out their actions within their physical environments whether through IoT devices like Seam’s mission or navigating their surroundings in the case of autonomous vehicles or manufacturing robots are the final piece of the agentic puzzle.
Conclusion
The market for tooling specifically built for AI agents of the future is the next stage of alpha in AI investments broadly speaking, since currently there still remains significant alpha in wrangling existing LLMs. A positive outlook on the advancement of LLMs’ tool-calling functionality indicates that these areas of interest will produce the new era of infrastructure startups upon which massive AI workforces will be built.